
Model Estimate and Residuals
The multiple linear regression model
 .
.
- In order to start over again, you need to clear the model formula first.
- From the above data the column
must be selected for the response variable
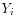 (dependent variable).
(dependent variable).
-
It builds a model formula for
the predictors
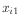 up to (independent variables)
in a form
up to (independent variables)
in a form
where we set predictor variables one by one for the model. A nonlinear transformation (e.g., log(x) or x^2) of the predictor x can be indicated by placing it in I(). For example, I(log(x)) or I(x^2).
The summary of multiple linear regression is obtained in the table below.
Summary table results.
The standard error ![]() for the estimate
for the estimate ![]() gives rise to
the null hypothesis
gives rise to
the null hypothesis
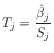 is distributed as the t-distribution with
is distributed as the t-distribution with
The prediction equation provides a fitted value
 against the standardized residuals
against the standardized residuals
© TTU Mathematics