
Model Selection and F-test
The multiple linear regression model
 .
.
- In order to start over again, you need to clear the model formula first.
- From the above data the column
must be selected for the response variable
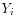 (dependent variable).
(dependent variable).
-
It builds a model formula for
the predictors
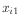 up to (independent variables)
in a form
up to (independent variables)
in a form
where we set predictor variables one by one for the model. A nonlinear transformation (e.g., log(x) or x^2) of the predictor x can be indicated by placing it in I(). For example, I(log(x)) or I(x^2).
The set of scatterplots for each pair of variables
can be produced in a matrix form
for the response ![]() and the explanatory variables
and the explanatory variables
![]() .
Collinearity appears in such a matrix as a close
linear relation between a pair of the explanatory variables.
.
Collinearity appears in such a matrix as a close
linear relation between a pair of the explanatory variables.
The objective of F-test is to determine
whether the variable in the full model  has “some effects” or not
in comparison with the sub model
has “some effects” or not
in comparison with the sub model ![]() "dropping" .
Then the hypothesis test problem becomes
"dropping" .
Then the hypothesis test problem becomes


To proceed the hypothesis test, the sum of squares within the respective model must be formulated by

 's are the fitted values under the model m=0 or 1.
Under the sub model
's are the fitted values under the model m=0 or 1.
Under the sub model

 degree of freedom.
Thus, we reject
degree of freedom.
Thus, we reject  .
Or, equivalently we can compute the
.
Or, equivalently we can compute the
| Drop | Source | Degree of freedom | Sum of squares | Mean square | F-statistic |
| <none> | |
 |
 |
 |
|
| k-th column | Between |
 |
 |
 |
 |
The above table summarizes the analysis of variance (aov) table for model selection.
Since we find a sub model ![]() plausible when we fail to reject
plausible when we fail to reject ![]() ,
we seek the highest p-value
,
we seek the highest p-value ![]() and decide to drop the corresponding variable
if
and decide to drop the corresponding variable
if
 .
.
© TTU Mathematics